CEEPR Working Paper 2019-020, December 2019
Sruthi Davuluri, René GarcÃa Franceschini, Christopher R. Knittel, Chikara Onda, and Kelly Roache

Most solar companies currently use credit scores to determine whom to approve for solar installations. Despite their widespread use, credit scores consider many aspects of a consumer’s credit history that are not directly related to utility payment; therefore, the FICO score is an imperfect proxy for predicting utility payment performance. This implies that traditional credit score cutoffs exclude people with low credit scores and those with insufficient credit history, which disproportionately hurts low-to-moderate (LMI) income households.
The goal of this research is: (1) to develop an alternative prediction model of default based on machine learning algorithms, specifically LASSO, SVM, and random forests; and (2) to compare its overall forecasting performance, as well as its implications for LMI consumers, to traditional credit metrics. We do so by developing a model that predicts the probability of non-delinquency of utility bill payments using a large data set of utility repayment and other financial data obtained from a credit reporting agency (CRA). We find that a traditional regression analysis using a small number of variables specific to utility repayment performance greatly increases accuracy and LMI inclusivity relative to FICO score, and that using machine learning techniques further enhances model performance.
A number of regression and machine learning techniques were used to predict utility bill delinquency. Among the variety of models that we explored, the random forest algorithm was clearly superior in terms of accuracy. Moreover, the random forest algorithm not only has better accuracy, but it also requires less data pre-processing. Finally, it is easier to interpret and runs more quickly.
The alternative scoring methods developed with traditional regression analysis and machine learning techniques were compared to standard FICO cutoffs, with a number of different metrics, including accuracy, default rate, and LMI inclusion.
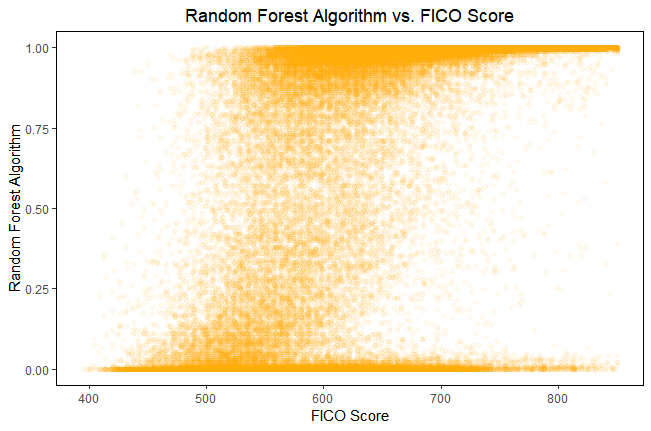
For example, Figure 1 (below) displays the probabilities of non-delinquency using the random forest algorithm against the individual’s FICO Score. There are many individuals who have a high probability of non-delinquency with the random forest algorithm, but do not have a very high FICO score, which demonstrates the amount of people that would have been rejected with the FICO cutoff, but accepted according to the random forest algorithm (“false negatives”). Additionally, there are quite a few data points with high FICO scores but do not have a very high probability with the random forest algorithm, who would be erroneously accepted (“false positives”). Figure 1 suggests that there are a high numbers of false negatives and false positives under traditional FICO scoring. Though the FICO Score is one variable used by the random forest algorithm, there are many other variables as well.
Importantly, the random forest algorithm, when tested with both 30 and 90 day definitions of delinquency, increase the number of LMI applicants approved. The random forest algorithm using a 30 day definition increases the number of LMI accounts approved by 11.4% to 14.0% depending on the stringency, while that using a 90 day definition increases LMI customers by 1.1% to 4.2%.
Finally, the impact of the alternative scoring methods on the profitability is estimated. The results shown in the paper demonstrate that the random forest algorithm leads to an increase in profits for the firm, which is a very significant result from our study. The random forest algorithm both benefits the customers, by accepting more LMI customers, and benefits the firms, by increasing profits.
We can decompose the increase in profits from the random forest algorithm to two sources. First is the increase in profits due to accepting new customers who would have been denied under the FICO score cutoff, or a decrease in false negatives (π from New Customers). Second is a reduction in losses from rejecting those who are accepted under the FICO Score cutoff but whom the random forest algorithm identifies as high-risk, or a decrease in false positives (“π from Less Delinquents”).
Overall, the random forest algorithm improves accuracy when compared to the FICO Score, offers access to solar energy for more LMI customers, and leads to an increase in profits when compared to the FICO score cutoff, regardless of the stringency of the industry standard.
References
Davuluri, Sruthi, René García Franceschini, Christopher R. Knittel, Chikara Onda, and Kelly Roache (2019) “Machine Learning for Solar Accessibility: Implications for Low-Income Solar Expansion and Profitability”, MIT CEEPR Working Paper 2019-020.
Further Reading: CEEPR WP 2019-020
About The Authors




